実務1ヶ月目(厳密には2週間)
前書き.
はじめましてumeと申します.
2025年7月15日(火曜日)から、東京の自社開発企業(TypeScript × Next.js × Go)でwebエンジニアとして働き始めました.
まだ働き始めて2週間ですが、感じたことや学んだことをこちらにまとめておこうと思います.
この記事を通じて、今まさにWebエンジニアを目指している方に、働くイメージを持っていただけたら幸いです.
もちろん、まだ入社して間もないため経験は浅く、感想も控えめではありますが、温かい目で読んでいただけると嬉しいです(笑).
本当は8月15日にちょうど1ヶ月の節目を迎えますが、キリが悪かったのでこのタイミングで振り返り記事を投稿します.
主に下記のことについて述べていきたいと思います.
入社前の私のスキルセット.
入社前にしていたこと。
初業務
学んだこと
感じたとこ(エンジニアの文化的な?)
まとめ
入社前の私のスキルセット
→基本的なwebアプリを1つ作成できるぐらいなレベル感です。(難しかったのははrailsのECサイトぐらいであとは簡単なもので恥ずかしいですがw).
1. アルゴリズム(Paiza Bランク).
Rails.
youtu.be.
Next.js✖️Typescript.
youtu.be.
react✖️javascript.
youtu.be
学んだ技術.

HTML5 CSS3 Tailwind CSS Bootstrap JavaScript (JS) TypeScript (TS) React Next.js バックエンド技術 Ruby Ruby on Rails Rspec データベース PostgreSQL SQLite MySQL その他(ツール・環境など) Git GitHub Docker Linux Web技術 セキュリティ
入社前にしていたこと
私は入社前、CSSとNext.jsの復習を重点的に行っていました。
理由は、実務で最初に任されるであろう「フロントのバグ修正やデザイン修正」をこなすために必要だと感じていたからです。
最終面接の逆質問で
「初めてやるタスクはフロントのバグ修正やデザイン修正をしてもらいます」と言っていただいたので、即戦力になれるよう事前に知識を補強しておきました。
この入社前の心情は、ようやく「webエンジニアになれた!」というポジティブな気持ちと、
「自分の実力で本当についていけるのか、会社の役に立てるのか…」というネガティブな不安が交錯していました。
でも過去「webエンジニアになる!」と決めて、下記の大切なものを手放して挑戦したぶん必ずやってやるという気持ちが勝ちました。
- 2年間付き合っていた大好きな彼女
(心の底から好きでしたが、自分から別れを切り出さなければならず、人生で一番辛かった経験です) - 安定した正社員の仕事
(勉強時間を確保するため、アルバイトで生活、逃げ道をなくしたかったです)
初めての業務
主に下記2つです。
- 環境構築
- フロントのバグ修正・デザイン修正(←今ここ)
環境構築
GitHubのREADME通りにコマンドを実行してスムーズに環境構築できました。
幸い大きなエラーもなく、無事セットアップ完了!
フロントのバグ修正・デザイン修正
実際にやる内容としては、
- Figmaで「ここが16pxなので同じく16pxに修正」
- バックエンドから返ってくるデータをカードに表示
- ボタンの色や数を動的に変更
など、話だけ聞くと「おっ、できそう!」と安心していました。
…が!
コードの規模が巨大すぎて該当ファイルが見つからない!!
Next.jsの構造でコンポーネントが細かく分割されており、ファイル数・ディレクトリ数が膨大。
どのファイルがどの画面に対応しているのか全くわからず四苦八苦…
(ちなみに今も全ては把握しきれていません)
救世主・AI登場
ここで救世主(ルーコードとクロードコード)が登場。
AIに助けてもらいながら、データ構造の解説や該当ファイルの特定、修正例の提案など何とかタスクを終えることができました。
ただ、「このままじゃAIに仕事を奪われるんじゃ…」という一抹の不安も(笑)。
学んだこと
- Talend API Testerの使い方(エンドポイントを指定してレスポンス確認)
- レイヤードアーキテクチャの概要
- Next.jsで () ディレクトリを使うとグループ化になること(例:/auth など)
- fetchで依存がある時は直列、依存がなければ並列取得でパフォーマンスUP
react-infinite-scroll-component(無限スクロール実装用ライブラリ)- Tailwind CSSの
cn関数(可読性アップ) as const(オブジェクトや配列をreadonly化)useTransition(重い処理をUIを固めずに非同期化)Set(配列と違い重複値を持たないコレクション)cmdk(ショートカット実装できるReactライブラリ)zustand(状態管理のライブラリ)useSWR(fetch+useEffect的なデータ取得フックでキャッシュやパフォーマンス◎)- TypeScriptの新しいインデックスアクセス型
- Cookie情報は検証ツールの[アプリケーション]から消せる
git rebase- インターセプトルーティング(Next.jsのモーダル重ね合わせ技術)
- パラレルルーティング(URL変えず複数ビュー表示 Next.jsの新機能)
- 他人のコードから学べることの多さ
感じたとこ(エンジニアの文化的な?)
- オフィスが驚くほど静か
- エンジニアも意外と感情的になる
- 自由(服装・髪型・働き方等)
- 実務未経験はフルリモートは非推奨(質問や雰囲気把握が難しい)
オフィスが驚くほど静か
前職が営業で、とにかくガヤガヤしたオフィスだった身としては、エンジニアオフィスの静けさは衝撃…
商談ロープレ・元気なあいさつ等で毎日賑やかだったのに、みんな淡々とパソコンと向き合っています。
エンジニアも意外と感情的になる
ロジカルな「無感情集団」だと思ってましたが、
エラーやバグで「なんでやねん!」とか「プログラミング何が楽しいねん」とか独り言を言う人も多くて、
解決したら「やった!」と嬉しそうにしていて、人間味を感じて親近感が湧きました。
自由
営業は服装・身だしなみなど色々厳しかったのですが、
エンジニアは服装も髪も自由だし、リモートもOK、
寝癖のまま作業してたり、寝転びながら仕事してる人も(笑)
ストレスフリーな職場だなあと感じました。
実務未経験はフルリモートは非推奨(質問や雰囲気把握が難しい)
特に未経験だと、
わからないことをすぐ質問できる環境の大切さをしみじみ実感。
出社してる方が気軽に相談でき、努力している姿もわかってもらえてチームの一員になりやすいなと思います。
まとめ
今は「webエンジニアになって本当に良かった!」と思っています。
まだまだ“名乗る”ほど仕事をこなせてはいませんが、
独学時代同様、泥くさく一歩ずつ愚直に進んで、
「○○さんいてくれて良かった」と言われるエンジニアになりたいです。
これからも毎月、学んだことや感じたことをこうやって記事に残していこうと思います。
ここまで読んでいただき、本当にありがとうございました!
誕生日データで学ぶ!Rubyのsort_byによるカスタムソートの実践例
前書き
- 配列のソートで新しいソートを見つけたので、忘却録として記事に残します。
やりたいこと
⇨条件分岐を利用して1つの配列を2つの条件で並び替える.
[誕生月,日にち]の要素の配列birth_datesをある基準でソートする
birth_dates = [ [4, 3], [3, 30], [3, 31], [4, 1], [12,31], [1,5], [10,23], [4, 2] ]
↓誕生日を4月2日以降で並び替える
birth_dates = [ [4, 2], [4, 3], [10, 23], [12, 31], [1, 5], [3, 30], [3, 31], [4, 1], ]
どうやってソートしたか
birth_dates = [
[4, 2],
[4, 3],
[10, 23],
[12, 31],
[1, 5],
[3, 30],
[3, 31],
[4, 1],
]
standard_dates = {month:4,date:2}
sorted_array = birth_dates.sort_by do |month,date|
#5月以降か4月2日以降(4月2日含む)の場合とそれ以外(1月、2月、3月、4月1日)で分ける
if (month > standard_dates[:month]) || (month == standard_dates[:month] && date >= standard_dates[:date])
[0,month,date]
else
[1,month,date]
end
end
p sorted_array #出力結果[[4, 2], [4, 3], [10, 23], [12, 31], [1, 5], [3, 30], [3, 31], [4, 1]]
sort_by解説.
公式
配列.sort_by{|要素|並び替える条件}
例. 小さい数字順に並び替え
numbers = [5, 2, 8, 1, 4]
sorted = numbers.sort_by { |num| num }
p sorted
# => [1, 2, 4, 5, 8]
注意:並び替える条件はデフォルトでは昇順になる。降順にしたい場合-をつける.
解説.
①[0,month,date]や[1,month,date]このように0や1をつける理由は後から[[4月2日以降],[4月1日以前]]のように並び替えるため.
②[0,month,date]と[1,month,date]は下記のように4月2日以降(0がつく)と以前(1がつく)で配列の条件を分ける.
[[0, 4, 2], [0, 4, 3], [0, 10, 23], [0, 12, 31], [1, 1, 5], [1, 3, 30], [1, 3, 31], [1, 4, 1]]
③sort_byの返り値は上記の並び替えの基準で並び替えた、元々の配列(birth_dates)を返す。 なので下記のように返す.
birth_dates = [ [4, 2], [4, 3], [10, 23], [12, 31], [1, 5], [3, 30], [3, 31], [4, 1], ]
まとめ
- sort_byは条件分岐を使うと複数条件でソートすることができる.
Rubyで配列をコピーするときの挙動まとめ──シャローコピーとディープコピーの違い
前書き
下記のようにaを別のオブジェクトとしてbにコピーする際配列と2次元配列では挙動が変わるので記事にまとめます。
a = [1,2,3,4] b = *a a = [[1,2],[3,4]] b = *a
結論
配列をコピーしたい⇨シャローコピー(浅いコピー).
二次元配列をコピーしたい⇨ディープコピー(深いコピー)
シャローコピー
⇨オブジェクトの「外側」だけをコピーし、内部で参照しているオブジェクト(配列やハッシュなど)はコピーせず、元のオブジェクトと同じものを参照し続けるコピー方法
配列の場合は外側の配列しかないので問題なし
#配列のコピー(シャローコピー) a = [1,2,3,4] #スプレット構文でコピー b = *a #これがシャローコピーになる(オブジェクトの「外側」だけをコピー) #aの要素の変更はbには影響しない a[0] = 1000 #aに新しい要素を追加してもbには影響しない a << 5 #bの出力(aの要素の更新、追加の影響を受けない) p b #=> [1, 2, 3, 4]
もし2次元配列をシャローコピーすると↓
#2次元配列のコピー a = [[1,2],[3,4]] b = *a #aの要素の変更はbには影響する a[0][0] = 1000 #aに新しい要素を追加してもbには影響しない a << [5] #bの出力(aの要素の更新の影響を受ける、追加の影響は受けない) p b #=> [[1000, 2], [3, 4]] =begin ↑なんでこんな挙動(更新の影響を受けて、追加の影響は受けないのか)になるのか? 二次元配列で下記のようにコピーすると a = [[1,2],[3,4]] b = *a aの[1,2],[3,4]の外側の[]が別のオブジェクトとしてbにコピーされる なので[1,2],[3,4]これ自体はaと同じオブジェクトを参照しているのでaの更新の影響を受ける。 追加の影響を受けないのは[1,2],[3,4]の外側の[]の変更だから =end
ディープコピー
⇨オブジェクトそのものだけでなく、内部で参照しているオブジェクトも再帰的に新しくコピーする方法
#どうやって2次元配列で別のオブジェクトとしてコピーするか⇨ディープコピー a = [[1,2],[3,4]] #外側の[]だけでなく[1,2],[3,4]も別のオブジェクトとしてbにコピーされる b = a.map(&:dup) #aの要素の追加の影響をbは受けない a << [5] #a更新の影響をb受けない a[0][0] = 1000 #aの要素の更新も、要素の追加の影響のどちらもbは受けていない p b #=> [[1, 2], [3, 4]]
まとめ
別のオブジェクトとして配列と2次元配列をコピーするときでは挙動が変わる.
配列のコピーはシャローコピー、2次元配列はディープコピー
Ruby 幅優先探索
幅優先探索とは?
⇨迷路などで用いる現在地から目的地までの最短経路を求めるアルゴリズム.
詳しい概念は↓.
www.youtube.com
問題
⇨スタートからゴールまで何マスあるかを計測する(スタートとゴールもそれぞれ1マスとして計算する)
maze = [
["S", 0, 1, 0, 0, 0],
[1, 0, 1, 0, 1, 0],
[0, 0, 0, 0, 1,"G"]
]
答え12マス
考え方
スタートからゴールまでの道のりを全て均等に調べていく(幅優先探索)。 ①現在地(スタート地点)を配列に入れる ここから ②現在地から上下左右に1マス進めるか調べる。例,上行けるか調べて、次は下‥次は‥ ③進めない場合の条件3つ⇨①障害物(数字の1)がある。②もうすでに訪れたマス、③フィールド外 ③進める場合の条件⇨上記以外(障害物がなく、初めて訪れるマス、フィールド内) ④進めない場合⇨次の方角を調べる ④進める場合⇨進める方角の座標を配列に入れる。 ⑤ゴールに着いたら処理を止める ここまでループ
コード
#--迷路の変数--
#迷路作成
maze = [
["S", 0, 1, 0, 0, 0],
[1, 0, 1, 0, 1, 0],
[0, 0, 0, 0, 1,"G"]
]
#訪れたマスを記録する配列
visited_routes = Array.new(3){Array.new(6,false)}
#スタートから何マス進んだかを記録する配列
masu_count = Array.new(3){Array.new(6,1)}
#迷路の中の障害物を表す変数
barrier = 1
#--1マス進めるかどうか確認する際に使う変数--
#1マス現在地から上下左右に進んだ時に迷路の外に進まないかチェックするための変数
maze_top,maze_bottom,maze_left,maze_right = 0,maze.size-1,0,maze.last.size-1
#現在地の上下左右に1マス進めるか調べるための配列
all_directions = [[-1,0],[1,0],[0,-1],[0,1],]
#--スタートとゴールの地点--
#現在地(スタート地点)を配列に入れる
current_location = [[0,0]]
#ゴールの位置を変数に入れる
goal_location = [maze.size - 1,maze.last.size - 1]
loop do
#現在地を表す配列から現在地を1番前から取得する
current_length, current_width= current_location.shift
#現在地の上下左右に1マス進めるか調べる。これは一つずつ調べる
all_directions.each do |length,width|
#上下左右に進んだ場合の場所をそれぞれ記録する
new_location_length ,new_location_width = current_length + length , current_width + width
#フィールド外に飛び出していないか調べる
next if new_location_length < maze_top || new_location_length > maze_bottom ||
new_location_width < maze_left || new_location_width > maze_right
#障害物(1)がないかともうすでに訪れたマスではないかを調べる
next if maze[new_location_length][new_location_width] == barrier || visited_routes[new_location_length][new_location_width] == true
#もしゴールに着いたら、スタートからゴールまでの最短の道のりが何マスかを出力する
return puts masu_count[new_location_length][new_location_width] = masu_count[current_length][current_width] + 1 if goal_location == [new_location_length,new_location_width]
#訪れたマスを記録する
visited_routes[new_location_length][new_location_width] = true
#スタートから何マス進んだかを記録する
masu_count[new_location_length][new_location_width] = masu_count[current_length][current_width] + 1
#次に調べるマスを現在地の配列に入れる
current_location << [new_location_length,new_location_width]
end
end
まとめ
- 幅優先探索を用いると迷路などの最短経路がわかる
Ruby 素数判定
素数判定とは?
⇨2以上の自然数で、1とその数自身以外に約数がない数.
⭕️素数⇨2,3,5,7など. 1とその数字(2,3,5,7)でしか割り切れない. ❌素数⇨1,4,6,8など 4は2で割り切れたり、6は3で割り切れたりする
1~100までの素数を判定してみる
今回わかりやすいようにメソッド名を「日本語」にしています。
def 素数?(number)
①return "#{number}素数ではありません" if number < 2
②(2..Math.sqrt(number)).each do |i|
return "#{number}素数ではありません" if number % i == 0 # numberが1とnumber自身以外の数字で割り切れたら素数ちゃう=1とnumber自身以外の約数があれば素数ではない。例えば6は1と6以外に2,3でも割り切れるから素数ではない
end
③"#{number}素数です"
end
(1..100).each do |number|
puts 素数?(number)
end
解説(考え方)
①、1は必ず素数ではないので素数?(number)メソッドの引数(number)に1が渡ってきたらすぐにメソッドの中の処理を中止する.
②、それ以外の数字(number)が渡ってきたらnumber % 2,3,4,5,6....numberまでの値で割り算を繰り返す。もし割り切れるものがその数値(number)以外に1つでもあれば素数ではないのですぐreturnでメソッドの処理を中止する。
③、②の処理でreturnされなかった場合素数なので素数である返り値を返す。
組み込みメソッドMath.sqrtとは?
Math.sqrt何ができる?
⇨平方根を求めることできる。例えばMath.sqrt(9)は平方根3が求められる
何が嬉しい?
⇨パフォーマンスが良い=大規模データにも対応できる(後で説明)
どうやって3になった?
⇨要は「どんな数を2回かけたら9になるか?」→ 3 × 3 = 9 なので、平方根は3。
(2..Math.sqrt(number))のように使うとどうなる?
⇨(2..Math.sqrt(9))の場合(2..3)として認識される。
上記のこれの何が嬉しいの?
⇨パフォーマンスが良い.
理由、素数の数字の処理の時に無駄なループがいらない.
例えば97という素数を調べるとき(2..97)とすると96回ループしますが(2..Math.sqrt(97))だと9回で済む。
注意点
⇨平方根が(2..1.4142)みたいになると、each文の中には処理が進まず、 ③"#{number}素数です"が実行される。
要は(2..Math.sqrt(2))みたいなときは1.4142という平方根になるので③"#{number}素数です"が実行される。
each文の中に進む処理は2以上の平方根になった時のみ
まとめ
- Math.sqrtはパフォーマンスをよく素数判定したい時に使う.
トークンベースの認証(jwt)の仕組みとセッションベースの認証との違い
前書き
セッションを使ったログインの仕組み以外にjwt(Json Web Token)という認証の仕組みを新しく.
学びました。自分の言葉で理解する事で記憶の定着を測ると共に初めてjwtを知る人にも分かりやすく.
理解していただけるように記事に残します。
筆者について
- 実務経験未経験のプログラミング学習初学者
対象者
認証が何か既にご存知の方
セッションベースの認証は知っているがjwtは初めて聞いた方
この記事でわかること
- jwtとセッションを使った認証の違い
jwtとは?
⇨「Json Web Tokenの略で複数ある認証(本人確認)方法の1つ(トークンベースの認証)」.
他にもセッションを使った認証やSNS(instagramなど)を使った認証がある。
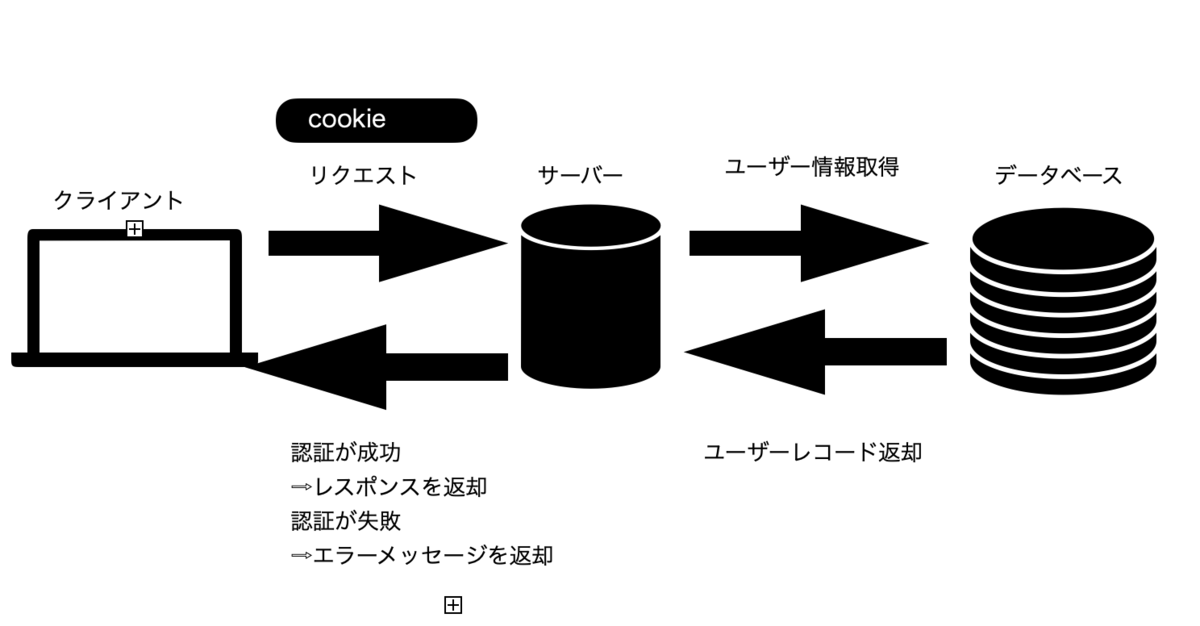
セッションベースの認証の仕組み(永続ログイン)
処理の流れ(初回ログイン後).
①クライアントからサーバーにリクエストを送る際にクッキーも付与してサーバーに送信.
②サーバーでクッキーの中のセッションidの有効期限を確認する。その後セッションidを使ってデータベースに該当のユーザーのレコードを取得.
③ユーザーのレコードのハッシュ化されたトークンとクッキー内の永続トークンをデータベースのハッシュ化されたトークンと認証する.
④認証が成功するとレスポンスを返却する。失敗するとエラーを返す.
良い点
セッション情報の更新がしやすい。(ユーザーが「ログアウト」または管理者が手動でセッションを削除すると、即座にアクセス不能にできる)
ユーザーごとに異なる権限設定を柔軟に管理
悪い点
サーバーに負荷がかかる
セキュリティとユーザビリティのトレードオフの関係がある(クッキーの中のセッション情報の有効期限が長いとログインを求められる頻度は低いのでユーザビリティが向上。一方セッション情報が盗まれたときは被害が拡大しやすい)
この認証が向いているアプリ.
⇨銀行などのユーザビリティよりセキュリティ性が重要視されているアプリ.
理由:セッション情報を即時無効化しやすい。jwtだと盗まれた後でも有効期限内だと使用可能.
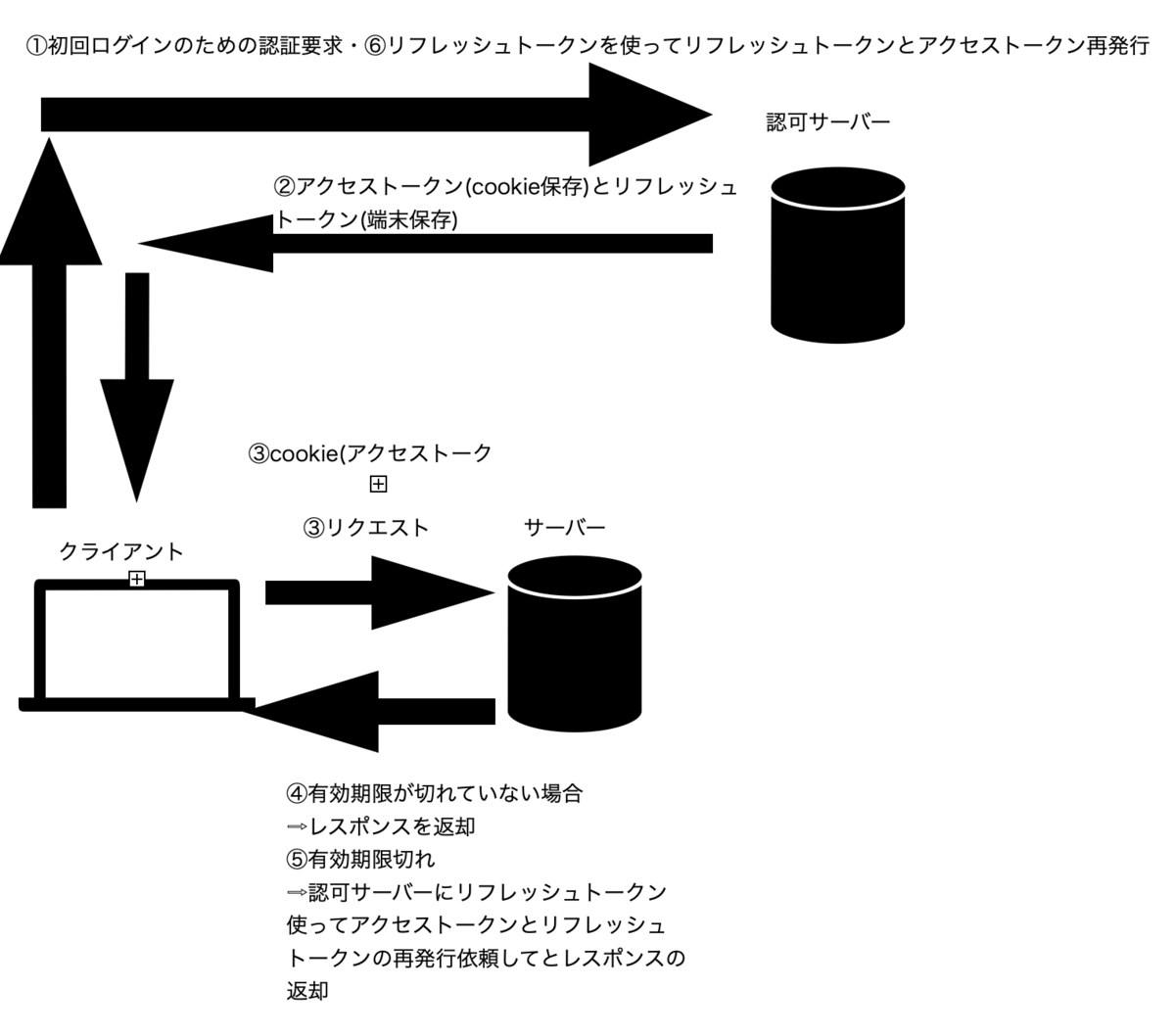
jwtの認証の仕組み(トークンベース認証)
処理の流れ.
①初回ログインのための認証要求.
②アクセストークン(cookie保存)とリフレッシュトークン(端末保存)をcookieや端末に保存する.
③リクエストをアクセストークン付きでwebサーバーに送信.
④webサーバーがアクセストークンを調べる(有効期限が切れていないかなど).
有効期限が切れていない場合.
⇨レスポンスを返却.
⑤有効期限切れ.
⇨認可サーバーにリフレッシュトークン使ってアクセストークンとリフレッシュトークンの再発行依頼してとレスポンスの返却
⑥クライアントがリフレッシュトークンを使ってリフレッシュトークンとアクセストークン再発行を認可サーバーに依頼する
良い点.
データベースを使わない認証なのでサーバーの負担が少ない.
モバイル、タブレット、pc端末とわず認証が実装しやすい.
悪い点.
どんなアプリに向いている?
⇨セキュリティよりユーザビリティに富んだアプリ(一度ログインしたら永遠ログインの状態を保持してほしいsnsなどのアプリなど)
まとめ
jwtとは数ある認証の仕組みの内の1つ
セキュリティよりユーザビリティの方にやや重きを置いているアプリの認証に向いている。
gemの選定基準(ポートフォリオ)
前書き
現在ポートフォリオを作成しているのですがどういう基準でgemを選定するのか.
不明確だったので基準を作ろうと思いました
前提
- 作成しているアプリは長期運用をする
gemの選定基準
情報量
拡張性
安定性
軸の理由.
①情報量.
⇨gemを使って実装する際に「やり方がわからない」で長時間時間を溶かすことのないようにするために情報量が多い方が時間を溶かさずに済む.
確認する指標:
①公式ドキュメントがある.
②zennやqiitaの記事数.
②拡張性.
⇨例えば今回ログイン機能を実装するとしてゆくゆくゲストログインやsnsログインを実装する予定の時に、後々このgemではsnsログインできないみたいなことが発生しないように拡張性があるgemを採用する.
確認する指標.
①後からこんな機能実装するだろうなぁ1~2個想像できる。
③安定性.
⇨長期的に開発者がgemのバグ修正、アップデートを繰り返している。またgem開発者のバグ修正しようと思うには、たくさんの人にそのgemが使用されているかも大切だと思います.
確認する指標.
①githubのコミット数.
②スター数.
③githubの更新日(長期的にメンテナンスしている?今後もされそう?).
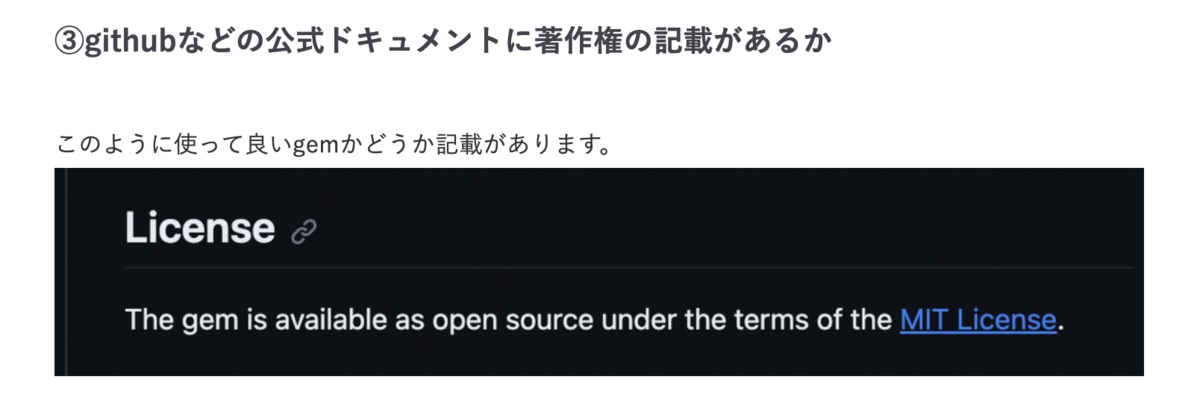 またそもそも使っていいgemか確認する必要がある
またそもそも使っていいgemか確認する必要がある